In the era of Large Language Models (LLMs), the search for generating responses with relevance has led to the emergence of Retrieval Augmented Generation (RAG). As LLMs are trained on large amounts of data available in the public domain until a specific date, this poses two problems: One is that it won’t be able to answer questions posed outside of its training data, and when it attempts to answer questions outside of its training data, it fabricates responses, also known as hallucination. Secondly, it fabricates responses when posed with questions on topics it was trained on but after the cut-off date of its training data. The approach of using RAG in retrieval is to help the model use its language knowledge acquired during training to generate precise responses on specific documents. However, what we often tend to neglect is that the heart of RAG lies in selecting an appropriate database, a decision that can profoundly impact the effectiveness of retrieval.
In the context of RAG, both vector and graph databases offer unique strengths. Vector databases, effective in handling high-dimensional embeddings, have proven effective in applications that require semantic search. However, when the focus shifts from individual data points to connections between those points, graph databases have proven to understand these complex relationships. This underscores the importance of, from a practical standpoint, why it’s crucial to realize that always turning to vector databases for RAG problems isn’t the answer. In the following sections provide challenges that are often faced in practical implementation of RAG with vector databases and how graph databases outshine it. In the following sections, challenges often faced in the practical implementation of RAG with vector databases are provided, along with how graph databases outshine them, illustrated through a case study.
Case Study: Enhancing Product Selling with Graph Databases
In a scenario, the task is to develop a RAG application that answers queries related to products. The knowledge base of the RAG system contains a vast dataset on various electronic products that are often seen on marketplaces. A particular record in such a dataset contains its title, description, ratings, price, identification number, image source, etc.
Starting with how we embed all this data, one might consider embedding everything into the database. However, when the dataset contains millions of records, embedding everything at that point does not make sense. Especially when fields like image source or ratings are irrelevant or unnecessary. So, we only embed the description columns of the dataset that answers user queries about the products, while the remaining data is stored as metadata in both vector database and graph database.
Challenges with Vector Databases
The following section describes the challenges with vector databases.

Figure 1: Output from the vector database-based RAG application when asked about complimentary products
- Failure in Complementary Cross Selling: When a customer queries about a product, often the generated response will only pertain to that product. Even if the customer asks about recommendations or suggestions for a complementary product, the application fails to answer it, as seen in Figure 1.
- Hallucination: If we change the prompt to generate complementary products that the customer might be interested in buying when they query about a particular product, the application still fails to do so. In this case, the system produces a fabricated response, as seen in Figure 2, i.e. this information about products isn’t present in the database. It’s important to note that prompt engineering is a tedious task, and even with the prompts provided, the system doesn’t guarantee precise results.
Figure 2: Output from the vector database-based RAG application with prompt modified to give complimentary products
- Failure in Explainability: While it’s possible to retrieve source nodes using vector databases, they fail to explain how they generated responses for complementary products when those products aren’t present in the database.
Solution with Graph Databases
The following section describes the challenges faced by the vector database that are overcome by graph database.
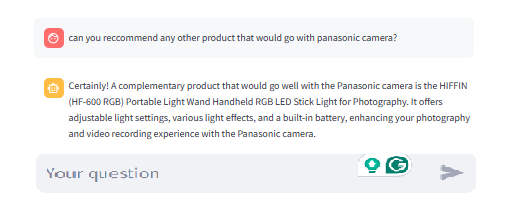
Figure 4: Output from the vector database-based RAG application when asked about complimentary products
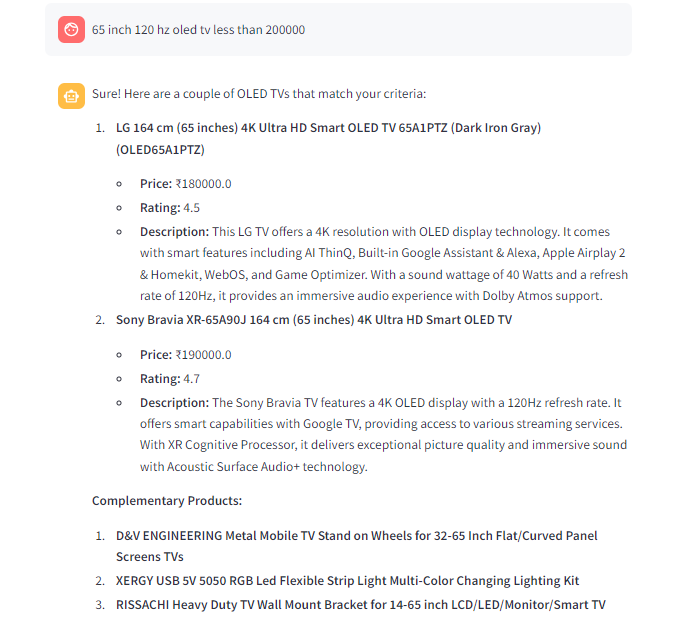
Figure 5: Output from the graph database-based RAG application with prompt modified to give complimentary products
- Success in Complimentary Cross Selling: Because a graph database can understand relationships, as demonstrated in Figure 3, the system can correctly retrieve complementary products even with a simple prompt. In a vector database, the system can’t do this because it doesn’t understand relationships. It just matches the query with what’s already stored.
- No Hallucination: As seen in Figure 4, when we change the prompt to generate complimentary products that the customer might be interested in buying when they query about a particular product, the application correctly suggests the complimentary products. This ensures that the customer is effortlessly presented with other complimentary products they may be interested in purchasing.
- Explainability: Similar to retrieval from a vector database, source nodes can also be retrieved through a graph database. However, unlike a vector database, a graph database can retrieve the source nodes for the complementary products the system suggests. Figure 6 illustrates how relationships are formed between the data points, and these relationships are crucial for retrieving precise complementary products.
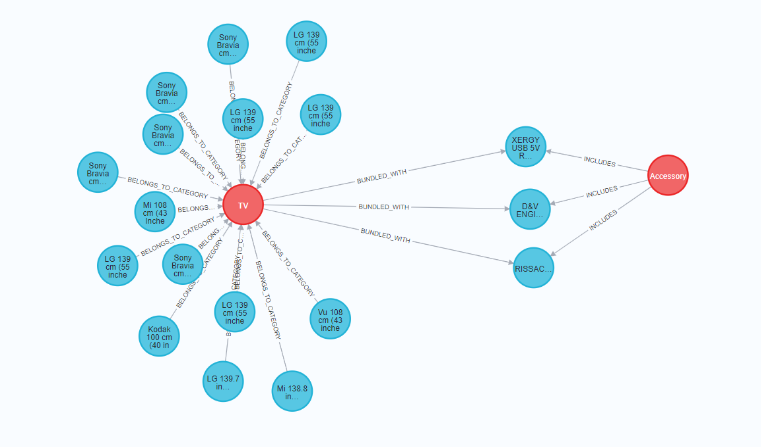
Figure 6: Graph with nodes and relationships in an electronic dataset
Bonus: Achieving Personalization with Graph Database
The graph database facilitates a deeper understanding of user preferences and behaviors. To illustrate this, consider a user, let’s call them User A, who purchases a smartphone accessory that complements their latest smartphone purchase. The graph database captures User A’s smartphone purchase along with the complementary accessory they bought.
Now, here’s how the graph database leverages the insights it gains: when another user, User B, asks for smartphone recommendations, the system infers that the complementary accessory purchased by User A may also be of interest to User B. In this way, the graph database enables personalized recommendations by leveraging contextual understanding.
Conclusion:
Success in RAG applications largely depends on the choice between a vector database and a graph database. RAG applications on a vector database can help us achieve significant performance in semantic search. However, when the need arises to understand complex relationships among data points, then a graph database for RAG applications offers more personalization.